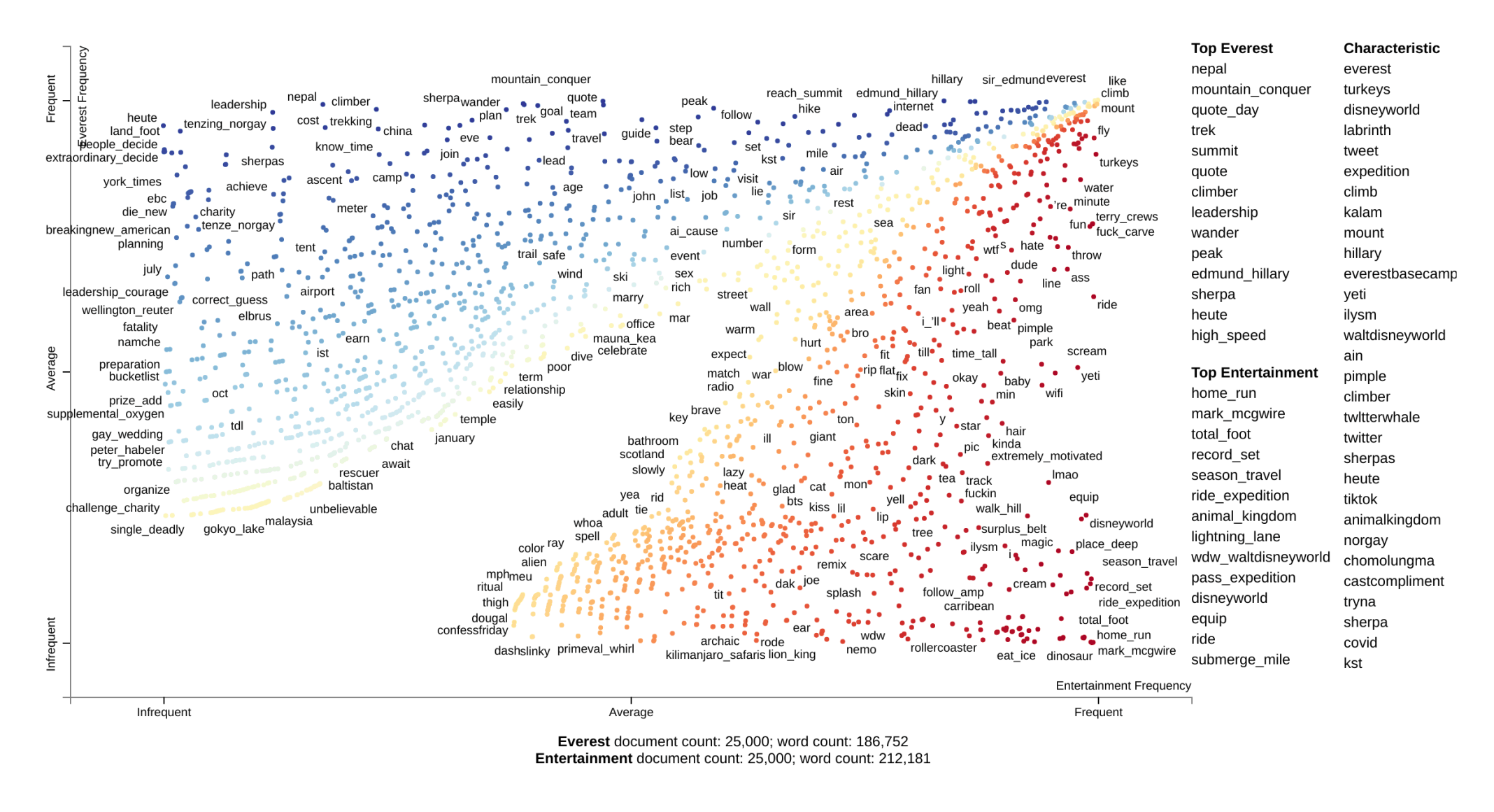
Social Media and Climbing
Interest in expeditions especially on the coveted summit, Everest, was slow to pick up over decades. But something changed in the late 1990s. While a direct correlation is not being drawn here, social media platforms also started around this period and truly took off in the 2000s.